Basics of Incident Management

- Published on
- /12 mins read/---
Definition
What is an incident? Incident is any interruption or disruption to normal IT services.
IT services : It is where you have the network services ,systems ,applications ,voice ,database as well as end user support related services.
Examples of Incidents - Router down ,database down , Payroll service down and issues reported reported by users ,non IT or IT users.
Incident management - Incident management is a critical IT Service Management (ITSM) process focused on restoring normal service operations as quickly as possible following an unplanned disruption, while minimizing the impact on business operations.
Requests generally encompass any formalized demand for service, change, or assistance from the support team. While incidents deal with unplanned disruptions, requests are structured and often predictable tasks. Example, Change Requests: Upgrading a server, deploying a patch.
SLA stands for service level agreement.It refers to a document that outlines a commitment between a service provider and a client, including details of the service, the standards the provider must adhere to, and the metrics to measure the performance.
Objectives
- Restore Service as Quickly as Possible
- Minimize Impact and Downtime
- Meeting SLA’s provided by the organization ,internal or external org i.e SLA’s set by client
- Client & customer satisfaction
- Improvement in the Business productivity
Inputs
- Phone call
- Web tool like snow(ServiceNOW) ,hp service center ,BSM remedy or email etc
- Incident can come from client or supplier
Organizations do categorize Incident management as sometimes Operation or Run Mode. Every year millions of dollar is spent to reduce operational cost in other words maintenance and operation.
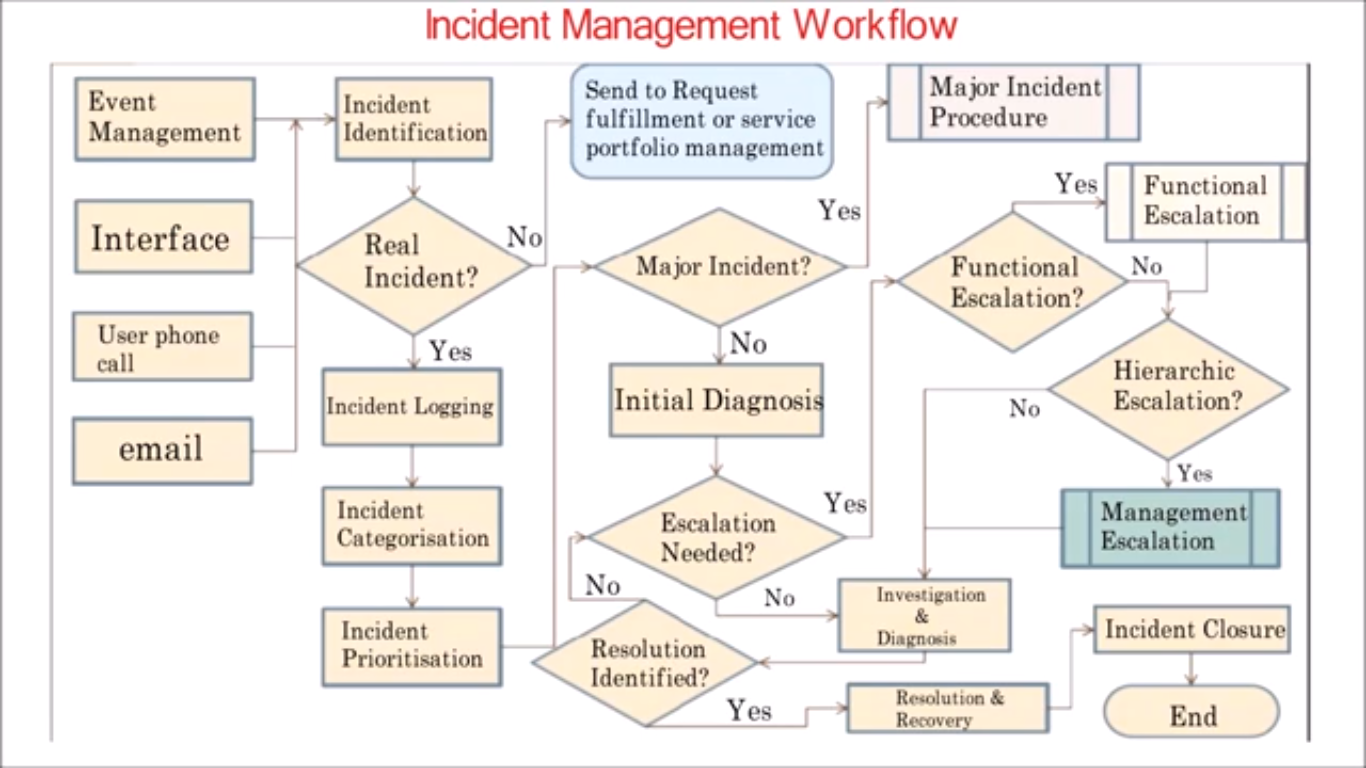
Process activities
It completely depends from organization to organization.A typical process activities includes but not limited to
| Step | Activity | Example |
|---|---|---|
| Incident Identification | The first step in incident management is identifying that an incident has occurred.This can be through various channels like automated monitoring tools, user reports, or proactive checks. | A network monitoring system detects a server outage, or a user reports an issue with a particular software application. |
| Incident Logging | Once an incident is identified, it should be logged in the Incident Management System (IMS) or helpdesk tool.This log should contain all relevant details, including the incident description, the time of occurrence, the user reporting the issue, and the severity. | An IT support team logs a ticket detailing the affected service, impact, and priority level in tools like ServiceNOW(snow) or any similar tools. |
| Incident Categorization | After logging, the incident is categorized based on the type of service or system impacted (e.g., network, hardware, software).This helps in determining the severity, appropriate resources, and response protocols. | Categorizing an incident as "Application Crash" or "Network Connectivity Issue" helps prioritize and route it to the appropriate team. |
| Incident Prioritization | Incidents need to be prioritized based on their impact and urgency.The priority determines the order in which incidents are addressed.Critical incidents affecting a large number of users or business-critical systems should be handled first. | A system-wide outage that affects multiple departments might be prioritized higher than a single user's issue with a minor application. |
| Incident Diagnosis | The support team or the designated personnel investigates and diagnoses the root cause of the incident. This may involve gathering more information, troubleshooting, or replicating the issue. | If a website is down, the team may check the server logs, perform network diagnostics, or verify DNS settings. |
| Incident Escalation | If the issue cannot be resolved at the initial support level, it may need to be escalated to higher levels (L2, L3, or specialized teams). This escalation ensures that the incident is handled by personnel with the expertise to resolve the issue. | If a Level 1 support agent cannot resolve a complex database issue, the incident is escalated to a Level 2 or database expert. |
| Incident Resolution | Once the root cause is identified, a resolution is implemented to restore the affected service. This could involve restarting services, applying patches, reconfiguring systems, or providing workarounds. | After identifying a malfunctioning software update, a rollback might be performed to restore the system to its previous functional state. |
| Incident Recovery | This involves ensuring that the service is fully restored and functional. After resolution, the incident is monitored to ensure that the solution has worked and that there are no further issues. | After resolving a server crash, the team may monitor system performance to confirm the issue is fully resolved and that there are no lingering problems. |
| Incident Closure | Once the incident is resolved and the service is restored, the incident is formally closed. The closure should include a final summary, any notes on the resolution, and verification that the affected user(s) or department is satisfied with the outcome. | The helpdesk closes the ticket once the issue is resolved, notifying the user that the incident has been addressed. |
| Post-Incident Review (Optional but Recommended) | After the incident is closed, a post-incident review (PIR) is conducted. This helps in analyzing the cause of the incident, evaluating the response, and identifying any improvements or preventive measures. | A review might show that a particular issue occurred due to a lack of monitoring, leading to recommendations for system upgrades or better alerting mechanisms. |
| Incident Documentation | Throughout the process, all actions, decisions, and communications related to the incident should be well-documented. This creates an audit trail and helps in knowledge sharing for future incidents. | Maintaining detailed records of incident tickets, including time logs, resolution steps, and outcomes, is crucial for compliance and knowledge base creation. |
| Communication and Notification | Keeping stakeholders informed about the status of the incident throughout the process is vital. This includes providing updates to affected users, departments, or customers. | IT support teams send periodic updates to users, notifying them of ongoing resolutions or expected timelines for fixes. |
| Continuous Improvement | Following the incident, teams should reflect on the handling process, identify any bottlenecks, and incorporate improvements into the incident management process to better handle future incidents. | After resolving multiple incidents of a similar nature, the organization may implement proactive monitoring or change its process to reduce future incidents. |
Escalation types
1. Hierarchical Escalation or Managerial escalation
Hierarchical escalation refers to the process of passing an issue or incident up the organizational hierarchy based on the level of expertise or seniority.
- Flow: Issues move from junior staff to more experienced or specialized team members.
- Purpose: Ensures that the right expertise is involved in resolving complex problems.
- Examples: When a junior developer escalates a critical bug to a senior developer or when a customer service representative passes a challenging customer issue to a supervisor. For example, if a customer asks for a refund or discount that an associate can't give, they may need to speak to a manager
- Advantages: Utilizes specialized knowledge, maintains efficiency, and provides better support.
- Challenges: Can lead to slower decision-making and reduced empowerment of frontline staff.
- Visual Representation:
Junior Developer → Senior DeveloperCustomer Service Rep → Supervisor
2. Functional Escalation
- Definition: Functional escalation involves routing an issue to a specialized team or department based on the specific function or domain related to the problem.
Flow: Issues move horizontally across functional areas (e.g., from development to testing, from IT support to network engineering).
Purpose: Ensures that issues are handled by experts in the relevant domain.
Examples: Escalating a database-related issue to the database administration team or forwarding a security incident to the cybersecurity team.
Advantages: Efficiently addresses domain-specific challenges.
Challenges: Requires effective communication between functions and clear handoffs.
Visual representation
Development Team → Testing TeamIT Support → Network Engineering
Remember that both hierarchical and functional escalation play crucial roles in incident management, ensuring that the right people with the right expertise are involved in resolving issues within an organization.
What is L1,L2 & L3?
In the context of incident management, the terms L1, L2, and L3 refer to different levels or tiers of technical support. Let’s break down what each level entails
1. L1 Support:
- Role: L1 or Level 1 support is the initial point of contact for users experiencing technical issues. It’s often provided by the user help desk.
- Responsibilities:
- Issue Screening: L1 personnel screen incoming issues, gather relevant information, and assess the severity.
- Basic Troubleshooting: They handle straightforward issues that can be resolved using predefined procedures or knowledge bases.
- User Assistance: L1 support assists users with common problems, such as password resets, software installations, and basic configuration.
- Example: If a user can’t log in to their email account, L1 support would guide them through the steps to reset their password.
2. L2 Support:
- Role: L2 or level 2 support comes into play when issues are more complex or require deeper technical expertise.
- Responsibilities:
- Advanced Troubleshooting: L2 personnel analyze incidents that couldn’t be resolved at L1. They use technical knowledge to diagnose and address issues.
- Configuration and Workarounds: L2 may perform basic configuration changes within applications or suggest workarounds.
- Interaction with Other Teams: If necessary, L2 collaborates with other teams (e.g., development, network) to resolve incidents.
- Example: Suppose an application is crashing due to a specific configuration.
3. L3 Support:
- Role: L3 or level 3 support handles the most complex and critical incidents.
- Responsibilities:
- Code Changes and Custom Solutions: L3 personnel deal with incidents that require code modifications, custom solutions, or deep system understanding.
- Root Cause Analysis: They identify underlying causes and address systemic issues.
- Escalation Point: L3 serves as an escalation point for unresolved L2 incidents.
- Example: If an application bug requires code changes or database adjustments, L3 support would handle it.
Each level builds upon the previous one, ensuring a comprehensive support system to tackle and incident.This structure can have more levels like L2.5 which can be a bot or specialized group that bridges the gap between L2 and L3 teams. Then L4 often an external vendor, subject-matter experts (SMEs), or highly specialized in-house experts involved to solve vendor specific problems like hardware failure etc.
Remember that these levels are part of a structured approach to IT support, allowing organizations to efficiently address user needs and maintain high-quality service.
Scenario of P4 incident Handling process
- A Server management team has L1 , L2 and L3 teams to handle incidents.
- Response Time: Updates are required every 1 hour until the incident is resolved or escalated. This ensures transparency and active monitoring.
- Resolution Time: The total resolution time allowed is 8 hours. If the incident is not resolved within this period, it is marked as a breached SLA.
- Time Allocation by Teams:
- L1 Team:
- Handles the incident for the first 4 hours (50% of resolution time).
- Tasks include initial triage, basic troubleshooting, and determining if escalation to L2 is required.
- L2 Team:
- Takes over for the next 4 hours if L1 cannot resolve the issue.
- Focuses on more advanced diagnostics and solutions.
- L3 Team:
- Receives the incident if it exceeds the 8-hour resolution time (100% of SLA time).
- These are breached incidents, requiring expert resolution and potential handling of penalties.
- Penalties for Breaches:
- If the incident resolution exceeds the 8-hour SLA, penalties might be applied.
- Penalties could include:
- Financial compensation to the customer (e.g., service credits).
- Internal consequences for failing to meet SLA compliance goals.
- L1 Team:
Incident management KPI’s
Key Performance Indicators (KPIs) are measurable values that demonstrate how effectively an individual, team, or organization is achieving objectives.KPIs can be categorized based on the area they measure
Purpose of KPIs
- Strategic Decision-Making: KPIs allow management to make informed decisions by succinctly communicating results.
- Focus and Improvement: They create a basis for decision-making and help focus attention on what matters most.
- Performance Evaluation: KPIs gauge output against targets, objectives, or industry peers.
Categories of KPIs
Strategic KPIs: High-level indicators used by executives track an organization’s overall performance toward achieving its long-term goals and objectives.
Examples include return on investment (ROI), profit margin, and total company revenue.
Operational KPIs: Analyze processes, segments, or geographical locations month over month (or even day over day). Used by managing staff to address questions derived from strategic KPIs.
Example :
MTTR-Mean Time to Resolve an Incident, Incident Resolution Time i.e average time to resolve reported issues etcCustomer-Focused KPIs: Measure per-customer engagement, satisfaction, and retention.
Example :
Net Promoter Score (NPS):Measures customer loyalty based on their likelihood to recommend your product or service ,Churn Rate- Percentage of customers lost over a given time.Process-Focused KPIs: These KPIs measure the efficiency, quality, and effectiveness of business processes, enabling organizations to optimize operations and meet strategic objectives.
Example :
First Contact Resolution RatePercentage of issues resolved during the first interaction with the customer should be 80% ,95% adherence to SLA terms.
Conclusion
Incident management, emphasize its vital role in maintaining business continuity and customer satisfaction. A well-structured process ensures quick resolution, efficient resource allocation, and compliance with SLAs. Continuous improvement(shift left) through monitoring KPIs and learning from past incidents is vital to any team or organization.
Hence organizations must invest in robust incident management practices, ensuring resilience and adaptability in the face of challenges, while fostering a culture of proactive service excellence.